我们下载文件时通常会使用浏览器或者迅雷这样的下载工具,这些工具大多具有高速下载(下载速度快)、断点续传(可以暂停之后继续下载)等特性。
现在我们自己开发的应用软件中也需要支持这些特性,我们该如何设计和实现了?本文主要围绕这一问题进行论述,并在文章最后分享了作者自己开发的高速文件下载库。
一个完善的文件下载库需要具有如下特性:
- 多线程分片下载
- 断点续传
- 磁盘缓存
- 最高下载速率限制及实时下载速率反馈(可选)
- 多协议支持,跨平台(可选)
1. 多线程分片下载
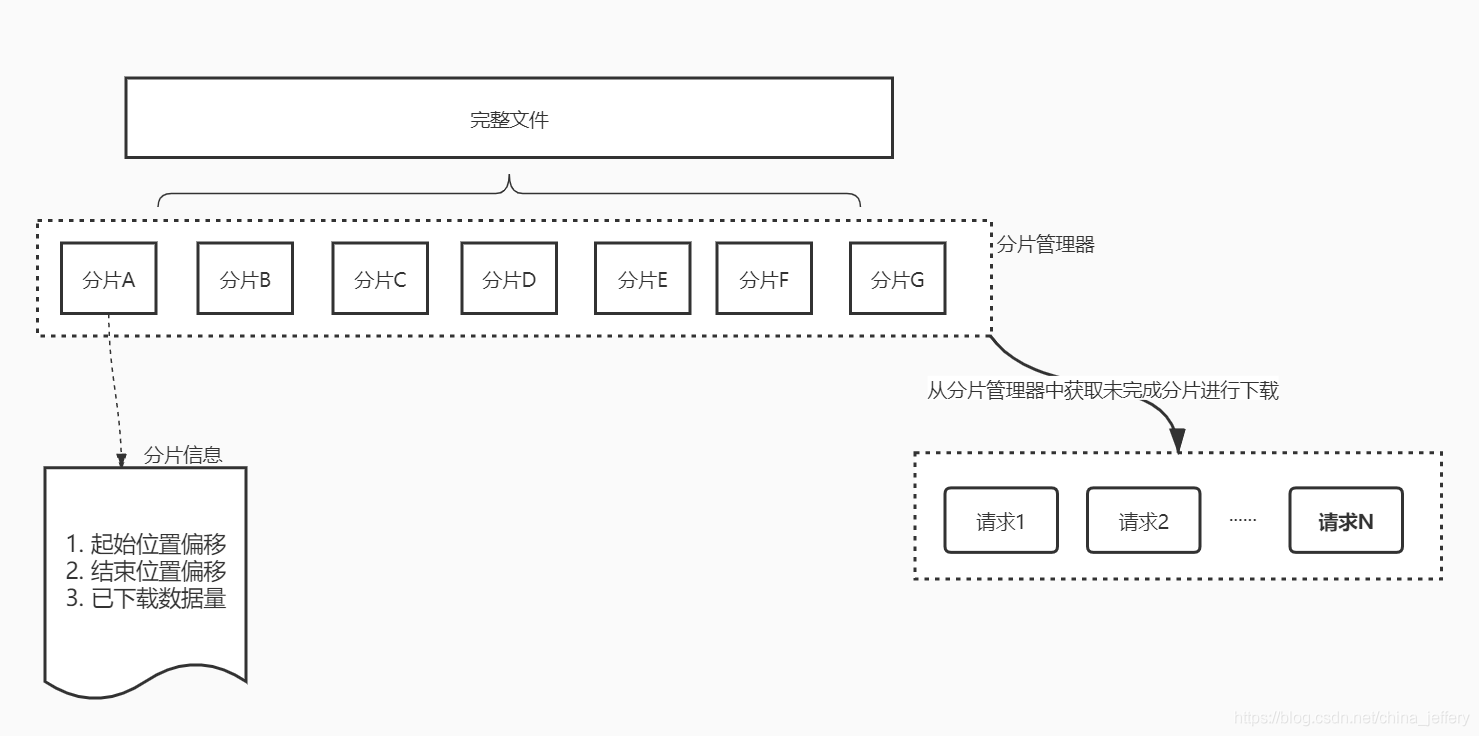
Chrome 浏览器和迅雷能实现高速下载的核心就是多线程分片下载(这里忽略迅雷的离线加速等技术),以 HTTP 协议为例,HTTP 协议支持在请求头中指明需要请求数据的起始和结束位置。我们可以开启多个线程同时进行不同的 HTTP 请求,这些请求分别请求同一文件的不同位置,我们将每个 HTTP 请求的内容称为“片”,在文件的所有片下载完成之后,我们再进行片的合并。
libcurl 中可以通过如下方式指定请求文件的某一区域:
1 | curl_easy_setopt(curl_, CURLOPT_RANGE, "1024-2048"); |
如何确定分片数量以及每片大小?文件分片有 2 种策略:
- 分片数量固定
除最后一片外,每片的Size=文件总Size/分片Num - 分片尺寸固定
分片Num=文件总Size/每片的Size,如果不能整除,还需要新建一个分片,将余数放到该分片中
无论采用哪一种分片策略,在确定分片 Num 和每片 Size 之前,我们都需要先向文件服务器发起一个请求来获取原始文件总 Size。
2. 断点续传
试想我们正在下载一个 4G 大小的文件,下载到一半的时候,忽然因为某些原因需要中止下载,等可以再次下载的时候,却不能继续上次的下载进度进行下载,那岂不是让人很抓狂。断点续传功能就是来解决这种问题的,虽然目前市场上的下载器都支持这些功能,但我们需要自己开发下载器的话,还是不得不自己来实现这个功能的。
断点续传原理主要是将已下载的数据信息(偏移、大小等)记录到某个文件中(我们称之为索引文件),下次下载前读取该文件中已下载信息,跳过已下载的内容,直接下载未下载的数据。
断点续传一般都会和多线程分片下载结合使用。
3. 磁盘缓存
文件下载中涉及的磁盘缓存都是磁盘的写缓存,主要是为了避免频繁的对磁盘进行写操作,降低磁盘 IO 的效率。
原理:将网络下载数据存入预先分配好的内存缓冲区,待内存缓冲区满之后,再一次性写入磁盘。
关于内存缓冲区,建议采用双缓冲机制,因为磁盘写入操作是一个相对耗时的操作,在将缓冲区写入磁盘时,该缓冲区是禁止写入的,因而此时网络下载的数据写入缓冲区将被阻塞,从而影响下载速率。
4. 限速及实时速率
最高下载速率限制有助于减少用户电脑带宽占用,而实时下载速率反馈可以让用户看到实时的下载速度。
因为采用的是多线程下载,假如最高下载速率限制为 N,则每个线程的最大下载速率为: N / 线程Num,但需要注意的是,如果当前活跃的线程数少于初始线程数时(如有的线程已经下载完了),需要重新计算每个线程的最大下载速率,否则总下载速率将会下载,无法达到最高下载速率。
zoe介绍
zoe 是我开发的一个文件下载库,支持如上所有特性的开源库,采用 C++开发。该库已经在多个产品中使用,其稳定性得到了验证。
该库原名为
teemo,teemo一词来源于英雄联盟游戏中的迅捷斥候,由于该库被灰产非法使用,导致代码被杀毒软件加入特征库,我闭源了原库,在修改代码后重新开源。
限于政策原因,在您看到该文章时,博客可能已经关闭了评论功能🥺
您可以通过在 blog-comment 项目中提交Issue来间接地发表评论🍀
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。




