Windows内存探索:从虚拟内存到堆管理的核心机制
在 Windows 开发中,对内存的理解深度,往往直接决定了一个程序的稳定性、性能与安全边界。那些看似突然的程序崩溃、难以追踪的内存泄漏,或是性能分析工具中令人困惑的内存数据,其根源常深植于我们对系统内存机制的理解盲区。
Windows 内存管理是一套层次分明、环环相扣的精密体系。从应用程序视角看到的连续“内存”,实际上是虚拟内存技术精心营造的抽象空间;支撑程序运行的物理资源,则通过分页机制在物理内存与磁盘间灵活流动。而开发者日常打交道的堆内存,则是系统在这一庞大抽象之上,为我们提供的一个兼顾效率与便利的关键服务层。更进一步,内存映射文件等高级特性,则打通了 I/O 与内存的边界,展现了系统统一管理资源的强大能力。
本文将为你厘清这些核心概念之间的内在联系与运作逻辑。我们不过度深入艰涩的内核细节,而是聚焦于为开发者建立清晰、准确、实用的认知模型。理解这些机制如何共同作用,能帮助你更有效地诊断内存问题、优化程序性能,并从根本上写出更为健壮可靠的 Windows 应用程序。
让我们从基本概念出发,逐步构建起关于 Windows 内存运作的系统性理解。
实模式下内存分配机制
在 8086 或者 80186 以前,我们运行程序时,操作系统会把程序全都装入内存,程序都是直接运行在物理内存上的。也就是说程序中访问的内存地址都是实际的物理内存地址。当计算机同时运行多个程序时,必须保证这些程序用到的内存总量要小于计算机实际物理内存的大小。
例如某台计算机总的内存大小是 128M ,现在同时运行两个程序 A 和 B ,A 需占用内存 10M , B 需占用内存 110M 。计算机在给程序分配内存时会采取这样的方法:先将内存中的前 10M 分配给程序 A ,接着再从内存中剩余的 118M 中划分出 110M 分配给程序 B 。这种分配方法虽然可以保证程序 A 和程序 B 都能运行,但是这种简单的内存分配策略会导致很多问题:
问题 1 :进程地址空间不隔离。由于程序都是直接访问物理内存,所以恶意程序可以随意修改别的进程的内存数据,以达到破坏的目的。有些非恶意但有 bug 的程序也可能不小心修改了其它程序的内存数据,就会导致其它程序的运行出现异常。这种情况对用户来说是无法容忍的,因为用户希望使用计算机的时候,其中一个任务失败了,不能影响其它的任务。
问题 2 :内存使用效率低。在 A 和 B 都运行的情况下,如果用户又运行了程序 C ,而程序 C 需要 20M 大小的内存才能运行,而此时系统只剩下 8M 的空间可供使用,所以此时系统必须在已运行的程序中选择一个将该程序的数据暂时拷贝到硬盘上,释放出部分空间来供程序 C 使用,然后再将程序 C 的数据全部装入内存中运行。可以想象得到,在这个过程中,有大量的数据在装入装出,导致效率十分低下。
问题 3 :程序运行的地址不确定。当内存中的剩余空间可以满足程序 C 的要求后,操作系统会在剩余空间中随机分配一段连续的 20M 大小的空间给程序 C 使用,因为是随机分配的,所以程序运行的地址是不确定的。
虚拟地址空间介绍
现在的 Windows 操作系统让每个进程都有自己的虚拟地址空间(Virtual Address Space)。以 32 位进程为例,每个进程都有0x00000000 ~ 0xFFFFFFFF(4GB)的虚拟地址空间,所以每个进程都可能分配到 0x123456 这样的内存地址,但这个地址不能在进程间相互访问。
因为这些都是“虚拟”的地址空间,所以这些“地址”都不能直接使用。CPU 在寻址的时候虽然是按照虚拟地址来寻址的,但是还要通过 MMU(内存管理单元)来将虚拟地址转换为物理内存上的物理地址:
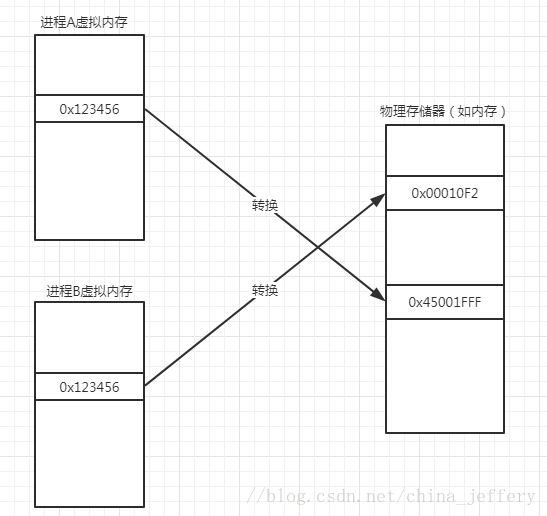
从图上可以看出,进程 A 和 B 虽然都有地址 0x123456,但它们分别对应的物理地址不一样。
虚拟地址空间分区
进程的虚拟地址空间虽然很大,但是它被划分成了很多分区,供 Ring3 层应用程序使用的用户模式分区并不大(一半不到),如图: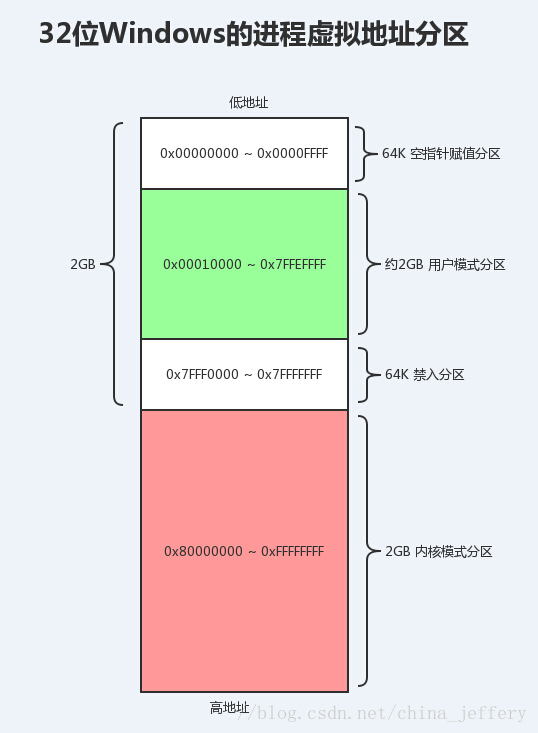
对于 32 位系统,虚拟地址的总空间为 4G([0x00000000, 0xFFFFFFFF]),其中 [0x00000000, 0x7FFFFFFF] 为用户模式分区(2G),供 Ring3 层应用程序使用;[0x80000000, 0xFFFFFFFF] 为内核模式分区(2G),供 Ring0 层内核驱动使用。
对于 64 位系统,理论上虚拟地址的可用空间应该为 64 位,最大可达 16 艾字节(EB)。面对这么大的内存量,显然,当今和可预见的未来里的计算机都不需要支持那么大的内存。相应地,为了简化芯片体系结构,并避免不必要的额外负荷(特别是在地址转译方面),目前 AMD 和 Intel 的 x64 处理器都只实现了 256TB 的虚拟地址空间。这是指,只使用了 64 为的虚拟地址中的低 48 位,虚拟地址仍是 64 位宽,在内存和寄存器中存储时仍然占 8 字节。未被使用的高 16 位必须被设置为与最高的被使用的位(即第 47 位)相同的值。
在这个规则下,低 128T 和高 128T 的地址空间的范围分别为:
1 | 0x00000000 00000000, 0x00007FFF FFFFFFFF |
从上面可以发现,在这两段地址的中间空余了很大的空间,可以方便后面处理器更新换代时进行扩展。
x64 Windows 在此基础上又做了进一步的限制,在 x64 处理器的 256TB 虚拟地址空间中,目前 Windows 只允许使用略微超过 16TB 的空间。这 16TB 的空间被分割成两个 8TB 的区域:
- 用户模式的 8TB,从 0 开始向上增长,结束于
0x000007FF FFFFFFFF。 - 内核模式的 8TB,从
0xFFFFFFFF FFFFFFFF开始向下递减,绝大多数结束于0xFFFFF800 00000000。
空指针赋值分区
Windows 将用户模式分区的低 64Kb 区域([0x00000000, 0x0000FFFF])设计为了完全不可访问,该区域称为空指针赋值分区。保留该分区的目的是为了帮助应用程序捕获对空指针的赋值,如malloc分配内存失败,就会返回 NULL。
如果进程中的线程试图访问该分区内的内存地址,就会引发访问违规。
虚拟地址空间的使用
虚拟地址空间的使用涉及到 3 个概念:页面大小、分配粒度、预定和调拨。
页面大小
虚拟地址空间被分成以“页面”为单位,因为硬件内存管理单元是以页面为粒度将虚拟地址转译成物理地址的。页面的大小根据不同的 CPU 不而有所不同。x86 和 x64 系统使用的页面大小都是4KB,而 IA-64 系统使用的页面大小是8KB。
IA-64 操作系统只能在 INTEL 安腾系列处理器及 AMD 部分服务器处理器运行,所以主流市场并不常见。
当应用程序在虚拟地址空间分配空间时,系统需要确保分配区域的大小正好是系统页面大小的整数倍。
分配粒度
当应用程序在从虚拟地址空间分配空间时,系统会确保所有分配区域的起始地址都是分配粒度的整数倍。分配粒度的会根据不同的 CPU 平台而有所不同,但目前所有的 CPU 平台的分配粒度都是使用64KB。也就是说,分配的起始地址 = 64 * N,这也正好跳过了空指针赋值分区。
通过 Windows 的GetSystemInfo函数也可以获得此分配粒度值。
上面所说的
分配粒度和页面大小的限制,只是针对于“应用程序”,系统内核自己不存在这样的限制。
预定和调拨
虚拟地址空间的使用分为 2 个步骤:
预定(reserve):告诉系统我们要从虚拟地址空间
预定哪一块区域,系统为我们保留这一块区域。预定的局域的起始地址和大小遵循上面介绍的分配粒度和页面大小的要求。因为预定的只是虚拟地址空间,不占用任何其他物理存储器,所以没有形成实质的开销。调拨(commit):预定的区域还不能使用,我们还需要为
预定的区域从页交换文件中调拨存储器,调拨之后我们才能使用该区域。
至于为什么要从页交换文件中调拨存储器?页交换文件如何与物理内存之间交互?在后面的“虚拟内存”章节中会详细介绍。
虚拟内存
虚拟地址空间只是操作系统为进程“虚拟”出来的一块地址区域,并不代表任何实际的空间。而页交换文件却对应了实际的空间,这个空间一般是磁盘上名为 pagefile.sys 的文件。
页交换文件的大小和位置可以在系统设置(系统属性 -> 高级 -> 性能 -> 设置 -> 高级 )中进行设置: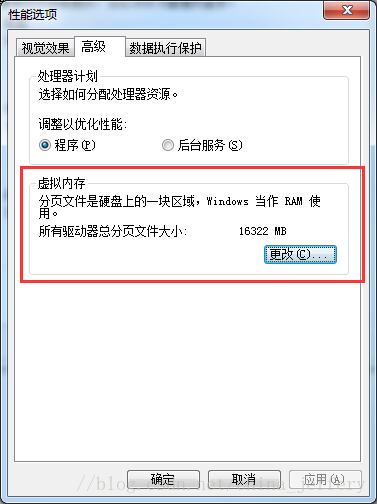
从微软的官方文档来看,“虚拟内存”等于“物理内存”+“分页文件”总和。可以把“虚拟内存”理解为 Windows 的一种内存管理机制。
虚拟地址空间、页交换文件、物理内存三者的关系如下图: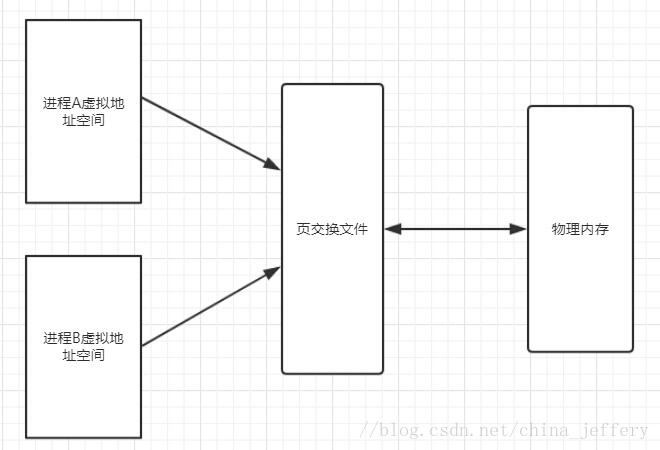
《Windows 核心编程》第 13 章关于“物理存储器和页交换文件”章节中讲到了“页交换文件、物理存储器之间的数据交换过程”,流程如下:
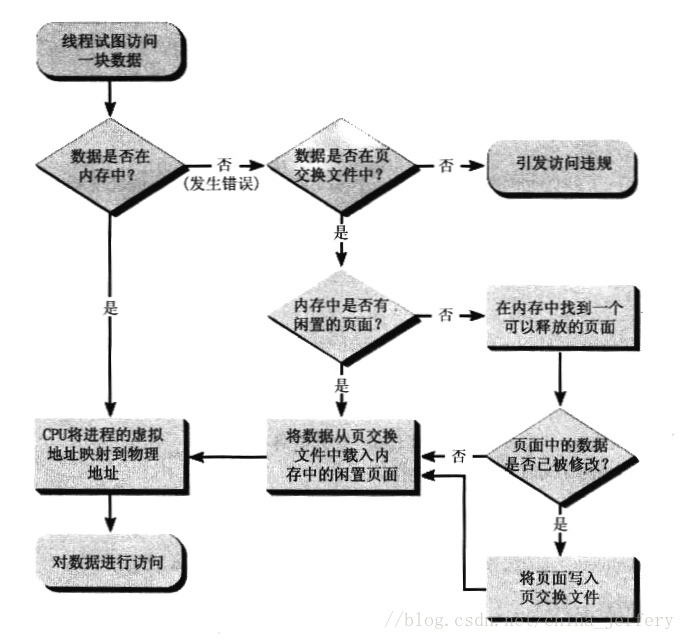
应用程序从进程的虚拟地址空间预定并调拨了一块地址区域时,起初这块区域只是从“页交换文件”中调拨的,这样作有个好处就是:因为还不确定何时才会使用这块区域,如果立即从物理内存调拨,会将占用很多的物理内存。
当程序读写该地址区域时,此时就会出现上面图上的页交换文件和物理内存之间的数据交换过程。
上面所说的内存是用户模式下应用程序所分配的内存,叫分页内存。还有一种内存叫非分页内存,仅供内核驱动使用,这种内存直接从物理内存分配,永远不会被交换,内核驱动也可以分配分页内存。特别对于 32 位系统,其非分页内存资源很紧张,驱动通常会使用分页内存。
用户模式下的应用程序只能分配分页内存,即便应用程序使用下面介绍的页面锁定方式,也只是避免了页面交换,但仍然使用的是分页内存。
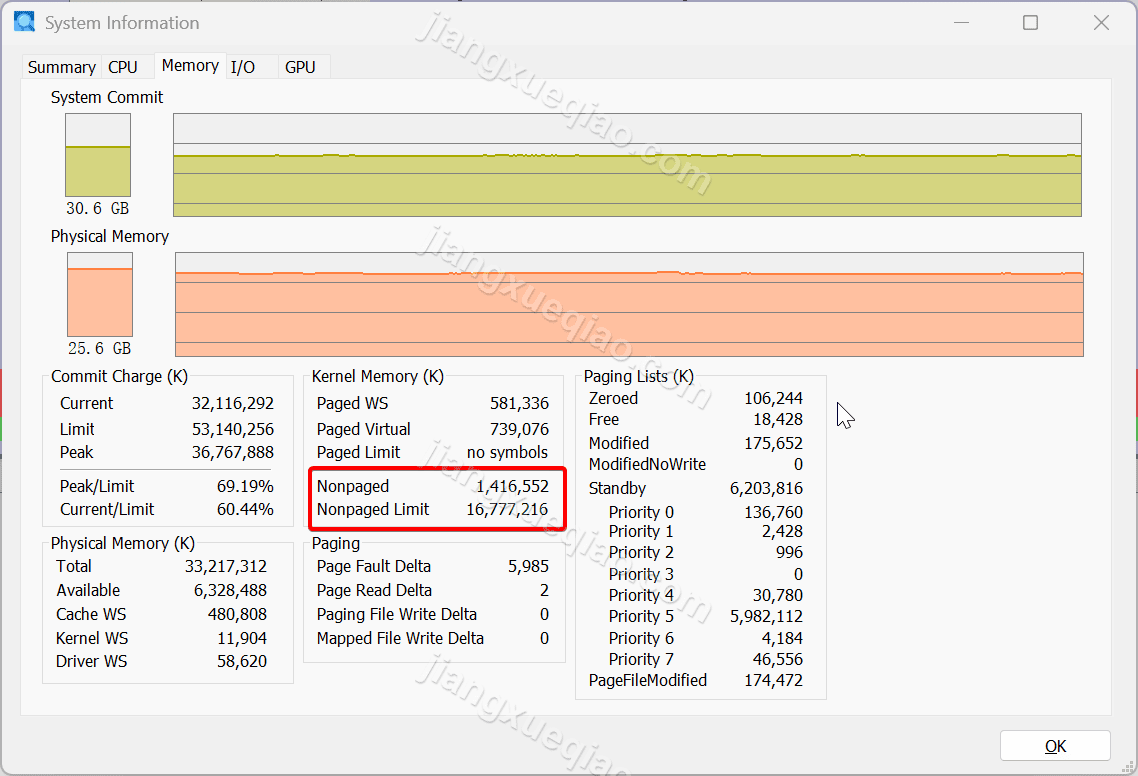
默认情况下,系统在启动时会根据硬件情况自动计算出分页与非分页内存的最大值。根据公开的资料可以查询到 Windows 的分页内存池/非分页内存池的极限值是:
| 区域 | x64 | x86 |
|---|---|---|
| 分页内存 | 128G | 650MB |
| 非分页内存 | 128GB | 256MB |
对于 x64 系统,非分页内存池的大小一般为物理内存的 75%,我们可以使用 Process Explorer 查看(View -> System Information)当前系统实际的非分页内存信息:
将页面锁定在物理内存
从上面的几节我们知道,当物理内存中没有闲置页面时,系统会将内存中的某些页面的数据写入到交换文件中,从而将该物理内存区域释放出来供后面的程序使用。
我们可以通过调用VirtualLock方法,将页面锁定在物理内存中,从而防止虚拟内存管理机制将页面交换至页面文件,而引起不必要的硬盘和物理内存之间的低效页面交换。
也可以通过调用VirtualUnlock方法解锁页面,允许系统对页面进行交换操作。
需要注意的是,锁定页面时系统会根据当前可用实际物理内存情况,以及进程工作集配额判定当前最大可锁定的页面的实际数量,超过此数量会引起一个错误。我们可以调用SetProcessWorkingSetSize可以改变一个进程工作集大小的配额,从而可以锁定更多的物理页面。
虚拟内存使用实例
虚拟内存方面的 API 属于页面粒度 API,通过这些 API 分配的内存的最小粒度是64KB。这些 API 分配(调拨)的内存区域最初都是位于“页交换文件”上面,当程序对该区域的某些“页面”(对虚拟内存的管理以页面为单位进行的)进行读写时,才会将这些页面交换到物理内存上面。
从“虚拟地址空间”章节中,我们知道虚拟地址空间要经过预定和调拨2 个步骤之后才能使用,这 2 个步骤都可以通过VirtualAlloc函数实现:
1 | LPVOID VirtualAlloc( |
当预定或者调拨的空间我们不在需要时,我们需要调用VirtualFree来释放该地址空间:
1 | BOOL VirtualFree( |
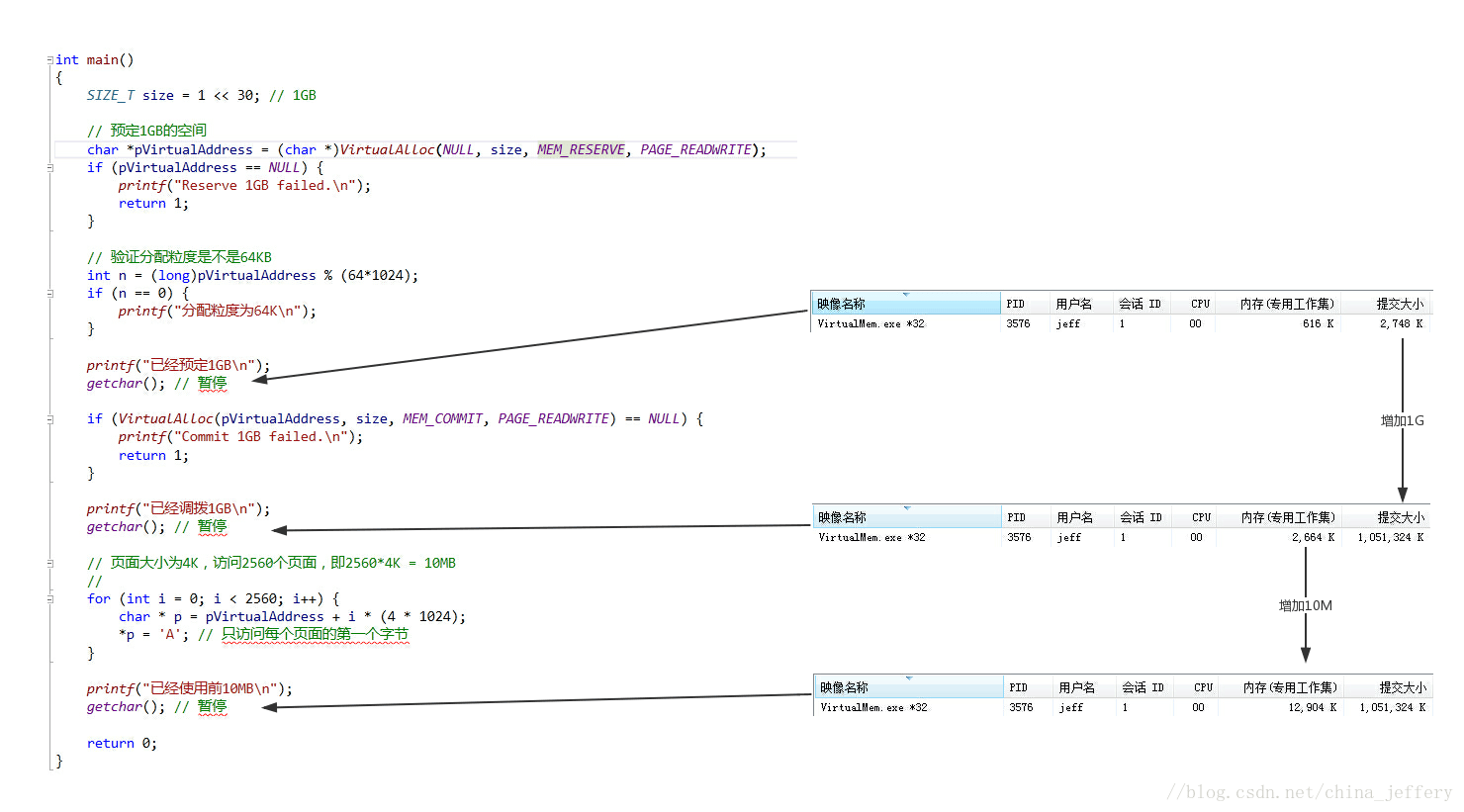
下面是的示例演示了在预定、调拨、使用等操作前后,进程的各项内存的占用情况:
1 |
|
在程序运行各个阶段进程的内存情况如下图:(“内存专用工作集”表示占用的物理内存的大小,“提交大小”表示调拨的页交换文件的大小)
内存映射文件
“内存映射文件”可以将硬盘上的文件映射到虚拟地址空间,这样就不需要将所有东西都放入到页交换文件中,比如系统有许多程序同时运行时,如果将这些程序文件都加载到页交换文件中,页交换文件将会变得非常大。事实上,Windows 也并没有将硬盘上的程序文件复制到页交换文件中,因为这样不仅会让页交换文件将会变得非常大,也会浪费很多时间,特别是可执行程序非常大的时候。
当用户要求执行一个应用程序时,系统会打开该应用程序的.exe文件,并计算出应用程序的代码和数据的大小,然后系统会在进程的虚拟地址空间预定一块地址空间,并注明与该区域相关联的物理存储器就是.exe文件本身。
当把一个位于硬盘上的文件(可以是.exe,.dll也可以是普通文件)映像用作地址空间区域对应的物理存储器时,我们称这个文件映像为“内存映射文件”。
现在我们可以对“虚拟内存”章节中的图进行完善了,加入“内存映射文件”部分: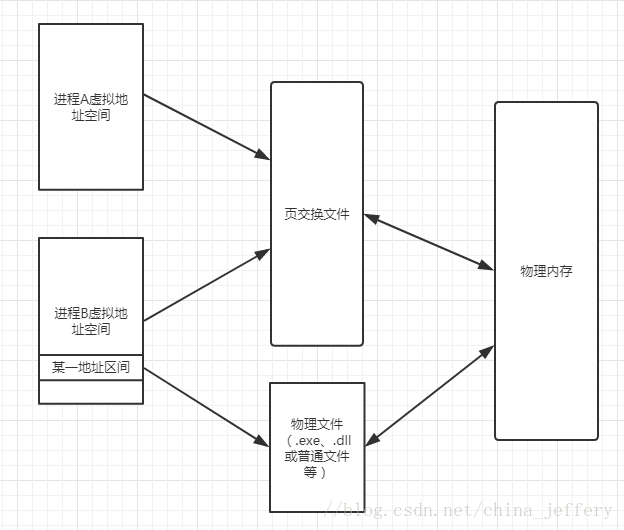
内存映射文件技术介绍
常用的有 Win32 API 的CreateFile()、WriteFile()、ReadFile()和 MFC 提供的CFile类都可以实现文件的读写操作。一般来说,以上这些函数可以满足大多数场合的要求,但是对于某些特殊应用领域所需要的动辄几十 GB、几百 GB、乃至几 TB 的海量存储,此时在以平常的文件处理方法进行处理显然是行不通的(效率低下,而且内存没那么大)。目前,对于这种大文件的操作一般是以内存映射文件的方式来加以处理的。
内存映射文件也是 Windows 的一种内存管理方法,提供了一个统一的内存管理特征,使应用程序可以通过内存指针对磁盘上的文件进行访问。通过文件映射将磁盘文件内容(全部或者部分)与进程虚拟地址空间的某个区域建立映射关联,可以直接对被映射的文件进行访问,而不必执行文件 I/O 操作也无需对文件内容进行缓冲处理。内存文件映射的这种特性是非常适合于用来管理大尺寸文件的。
大文件读写实例
通过 C++调用系统 API 实现文件映射的步骤大致如下: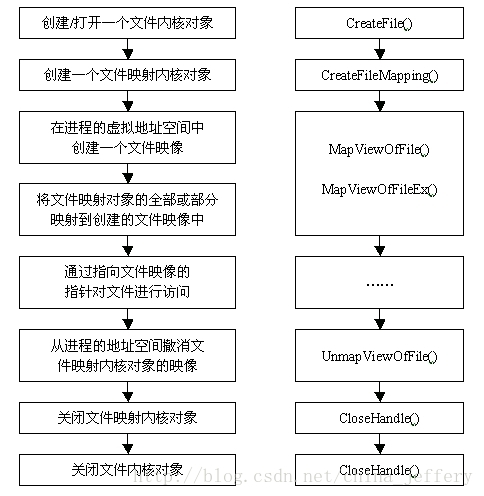
本示例首先在D:\生成一个大小为 1GB 的BigFile.data文件,然后使用内存映射技术将该文件内全部填充字符 A,随后读取其中的第20000~20100字节,并将这些字节修改为字符 B,然后再次读取已验证是否修改成功。
1 |
|
内存对齐
不是所有的 CPU 都能访问任意地址上的任意数据的,有些 CPU 只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
尽管内存是以字节为单位,但是大部分处理器并不是按字节块来存取内存的,它一般会以双字节、四字节、8 字节、16 字节甚至 32 字节为单位来存取内存,我们将上述这些存取单位称为内存存取粒度。
如果数据存储时是按照内存存取粒度对齐的,那么处理器就可以在一个内存访问周期内完成数据的读取;反之,如果数据没有对齐,可能需要多个内存访问周期才能读取完整的数据。
内存对齐规则
在 C/C++ 中,编译器会在结构体(联合体、类)成员之间插入填充字节,以确保每个成员都按照特定的对齐要求进行存储,以提高内存访问效率。
每个编译器都有自己的默认对齐系数(也叫对齐模数)。GCC 默认对齐系数为 4,MSVC 32 位默认对齐系数为 8,MSVC 64 位默认对齐系数位 16。
我们可以在代码中通过预编译命令#pragma pack(n)来指定对齐系数,n 可以为 (1, 2, 4, 8, 16)中的任意一个。
下面是 #pragma pack 命令的基本用法:
1 |
假设在一个结构体(联合体、类)中,最大数据类型长度为 m,编译器对齐系数是 n,则将 min(m, n) 称做对齐单位,也叫有效对齐值,这里记为 s。
对齐分为成员对齐和结构体(联合体、类)整体对齐。
- 成员对齐规则:第一个成员相对于结构体首地址的偏移量始终为 0,以后每个成员(数据类型长度记为 k)相对于结构体首地址的偏移量都为
min(k, s)的整数倍。 - 整体对齐:结构体的总大小必须是有效对齐值 s 的整数倍。
从内存对齐的规则可以看出:`
- 除第一个成员外,每个成员的偏移量:
min(k, min(m, n)) - 如果设置的对齐系数 n 大于类中最大数据类型长度 m 时,则该设置实际是不起作用的。
- 当对齐系数 n == 1 时,整个结构体的大小为所有成员长度之和。
示例
<原文出自: jiangxueqiao.com,请尊重原创>
在 64 位系统上编译下面的测试程序,已知在 64 位系统上各类型占用字节数如下:
1 | char 1字节 |
示例代码如下:
1 |
|
按照上面所讲的内存对齐规则,分析如下:
因为结构体中最大的数据成员长度为 int(即 4 字节),而且#pragma pack(8)指定的对齐系数为 8 ,所以有效对齐值 s 为 min(4, 8) = 4。
下图是结构体 A 按照 4 字节对齐的内存布局,内存填充在 s4 后面,而不是填充在 c 后面。另外,图中的内存地址按照从下向上的方向增长的。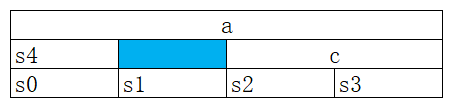
从图我们很容易知道sizeof(A) = 12。
堆
应用程序虽然可以使用页面粒度的函数(如VirualAlloc)来分配一个最小为4KB或8K的内存块,但是很多时候我们并不需要分配这么大的内存块,我们可能只需要 1K 或 2K 的内存,那么这个时候无论从内存的使用率,还是从性能的角度来看,再分配这么大的一个内存区域显然不是最优的了。
为了满足这种需求,Windows 提供了一个被称为“堆管理器”的组件,它负责管理大内存区域中的内存分配,这些大内存区域就是通过一些页面粒度的内存分配函数(如VirualAlloc)来预定(reserve)的。
堆管理器中的分配粒度相对比较小:在32位系统上是8字节,在64位系统上是16字节。
堆管理器已经被 Windows 系统精心设计,在这些小内存分配的情况下会进行内存使用率和性能两个方面的优化。
进程的默认堆
每个进程至少有一个堆,那就是进程的默认堆。进程的默认堆是在进程启动的时候创建的,而且在进程的生命周期中永远不会被删除。
“默认堆”的默认大小为1MB,但是可以通过/HEAP链接器编译器选项来指定一个更大的起始大小。这个大小值只是初始的保留内存大小,后期根据需要它可以自动扩充。
应用程序可以调用GetProcessHeap来获取进程的默认堆,也可以通过调用HeapCreate函数来创建额外的私有堆,当一个进程不在需要一个私有堆的时候,它可以调用HeapDestory来释放虚拟地址空间。
crt 堆
C 语言的malloc,free函数以及 C++的new,delete都是从堆上分配和释放内存的。但是他们所使用的堆不是进程的默认堆,他们使用的是私有堆。可是我们在使用malloc函数之前并有进行任何私有堆的创建操作呀? 因为malloc函数使用的这个私有堆不需要程序员来创建,而是在 C 或 C++运行时库 DLL 的启动代码_DllMainCRTStartup中自动创建的。下面通过解析malloc函数的调用过程来说明这一点。
malloc函数的定义在malloc.c文件中,调用流程如下:
(以Microsoft Visual Studio 10.0为例,malloc.c文件路径为C:\Program Files (x86)\Microsoft Visual Studio 10.0\VC\crt\src)
1 | (1). void* __cdecl malloc(size_t const size) |
_heap_alloc 的定义如下:
1 | __forceinline void * __cdecl _heap_alloc (size_t size) |
从上面的代码中,我们可以看到分配内存块的时候使用的是_crtheap句柄标记的堆。那么_crtheap堆是何时创建的了?
我们从heapinit.c文件中的_heap_init函数可以看到_crtheap堆的创建过程:
1 | HANDLE _crtheap=NULL; |
从上面的代码,我们可以看到,创建的私有堆句柄存放在一个全局的_crtheap变量中,后面每次调用malloc函数都是从该堆分配内存块。
Win32 堆函数
我们最常用的 Windows 堆函数如下:
HeapCreate或HeapDestory— 创建或删除一个私有堆HeapAlloc— 分配一个堆内存块HeapFree— 释放一个原先由HeapAlloc分配的内存块HeapReAlloc— 增长或缩减一个已分配的内存块的大小HeapLock或HeapUnLock— 控制堆操作的内存访问HeapWalk— 列举一个堆内部的内存项和区域。
内存管理 API 分层结构
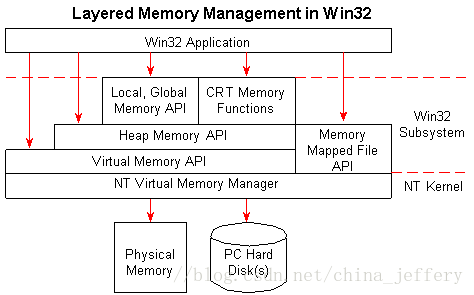
从上图可以看到,虚拟内存机制(Virtual Memory)是 windows 内存体系的基础,无论你是使用堆,还是使用内存映射文件,它们的底层都是基于虚拟内存来实现的。
从上往下,每一层的 API 在内部会依次调用下一层的 API。下图中列举了每层 API 中经常使用的函数:
- CRT Memory Functions:malloc, free, new, delete
- Local和Global Memory API: LocalAlloc, GlobalAlloc (这 2 个函数现在不建议使用,为了兼容以前的老代码才保留下来的)
- Heap Memory API:HeapCreate, HeapAlloc, HeapDestory
- Virtual Memory API:VirtualAlloc, VirtualFree
- Memory Mapped File API:CreateFileMapping, MapViewOfFile, MapViewOfFileEx, UnMapViewOfFile
跨模块堆释放问题
在《Windows 核心编程 第五版》第 19 章 DLL 基础(511 页)中给出了一个建议:
“当一个 MT 版本的模块如果提供一个内存分配函数的时候,它必须同时提供另一个用来释放内存的函数。”。
说得更加直白一点就是,“对于 MT 的模块,不要跨模块进行内存释放。”。但是核心编程这本书上面没有具体分析原因,本文就来分析具体的原因。
不同堆分配的内存块不能相互释放。
Windows 的堆管理器对每个进程都维护了多个“堆”,我们从每个“堆”中分配处理的内存块的地址都不一样。所以我们不能将从“堆 A”中分配出来的内存块拿到“堆 B”中,让“堆 B”来释放,这样就会导致程序异常。
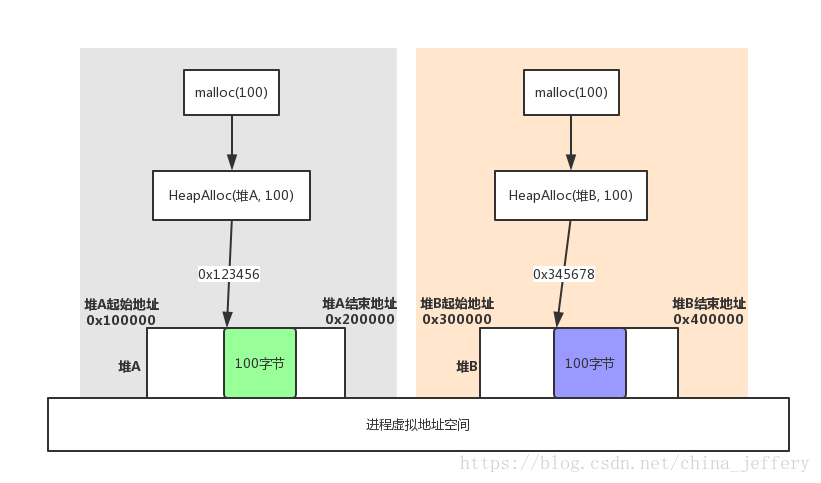
如上图,通过malloc函数从“堆 A”中分配 100 字节内存块,内存块地址为0x123456;从“堆 B”中分配 100 字节内存块,内存块地址为0x345678.
如果将0x123456这个地址拿到“堆 B”中去释放,势必会导致异常,因为“堆 B”中没有这地址。
那么我们是不是可以使用HeapFree函数来释放hHeap参数指定的“堆”中的任何内存块了。答案是:不能。
回忆前面介绍的HeapFree函数,
1 | BOOL HeapFree( |
这个函数只要求传入了内存块的起始地址指针,但没有要求传入需要释放的内存块的大小,那么该函数是如何知道起始地址指针指向的内存块的大小了?
我们可以简单的理解为,HeapAlloc函数每次分配内存块的时候都会额外分配一点空间用于存储一个结构体,该结构体中存储了本次分配的内存块的大小等信息。大致如下图: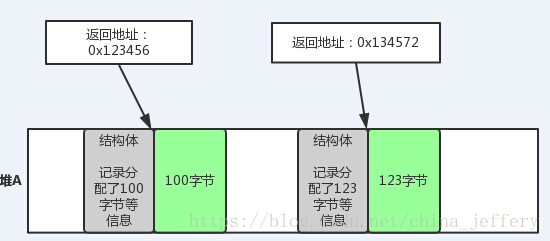
所以,HeapFree函数首先会通过lpMem指针计算出“结构体”的地址,然后从结构体中获取到分配的内存块的具体大小,最后执行释放操作。
基于上面的原因,我们不能在HeapFree函数的lpMem参数中传入随意的地址,因为该地址处可能没有存储用于存放内存块信息的结构体,所以释放操作就会失败。free函数也一样,因为free函数内部也是调用的HeapFree函数。
**MD 模块内存可以相互释放。**为什么 MD 模块内存可以相互释放,而 MT 模块的却不可以了?
我们先分析为什么 MT 模块的内存间相互释放会崩溃?
现在有 2 个模块(A.dll和B.dll)都是使用MT运行时库,即加载的静态库libcmt.lib(可以参考理解 Visual C/C++ 运行时库),在A.dll中使用malloc分配 100 字节的内存,malloc返回的内存地址为0x123456。然后将该地址传给B.dll,在B.dll中调用free函数来释放这个内存。如图: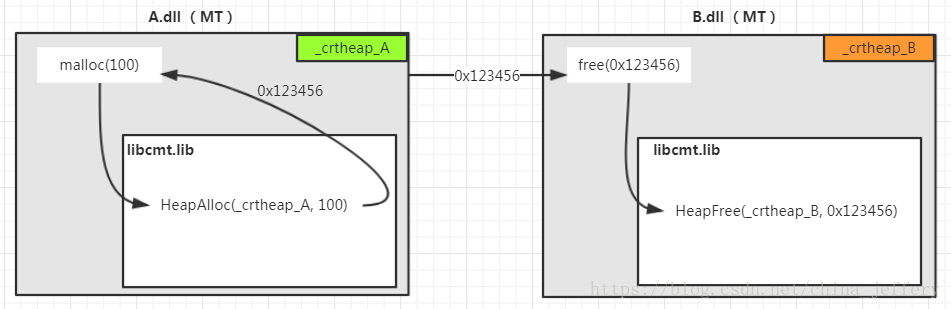
从“堆”章节我们可以知道,DLL 在启动代码_DllMainCRTStartup中会建立一个“堆”(堆句柄存放在_crtheap 变量中),所以 A.dll 和 B.dll 中都会有一个 crt 堆。
为了区分,我们将A.dll中的crt堆称作_crtheap_A,B.dll中的crt堆称作_crtheap_B。
从上面图可以看到,A.dll中malloc的内存拿到B.dll去中去free,就相当于从堆_crtheap_A中分配的内存拿到另一个堆_crtheap_B中的释放。第一节已经解释了为什么不能这样做了。
现在我们分析为什么 MD 模块的内存间相互释放不会崩溃。
还是 2 个模块(A.dll和B.dll),但是现在他们都是使用MD运行时库,即加载的动态库msvcr100.dll,程序的代码的过程和上面一样,还是在A.dll中使用malloc分配 100 字节的内存,malloc返回的内存地址为0x123456。然后将该地址传给B.dll,在B.dll中调用free函数来释放这个内存。但是这个时候程序却不会崩溃,通过下面的图我们基本可以明白原因了,如图: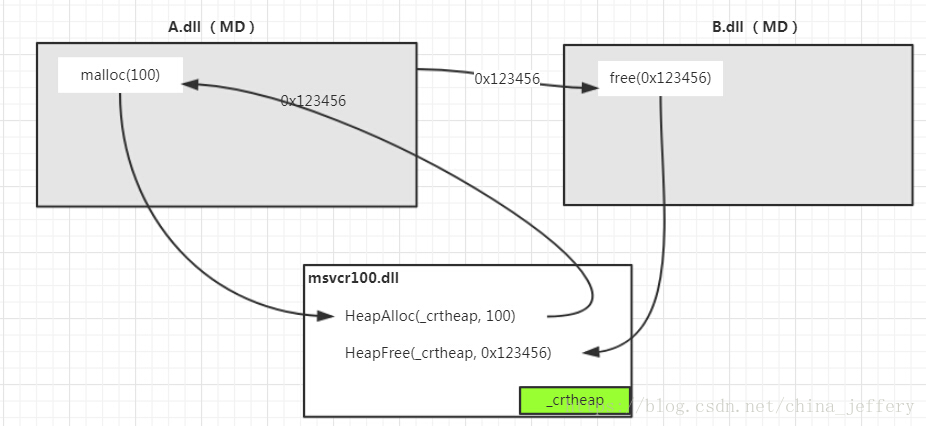
因为 A、B 两个 dll 都是链接的·msvcr100.dll·,同一个 dll 在一个进程只会被加载一次,所以进程中只会有一个 crt 堆(_crtheap),malloc和free都是运行时库提供的函数,所以都会调到运行时库里面去,然后从运行时库里面的_crtheap分配和释放内存块。因为分配和释放都是在同一个堆上,所以不会崩溃。
使用 std::string 跨 MT 模块传参
我们开发了一个 DLL,该 DLL 的运行时库采用 MT 模式链接,在为该模块定义接口函数时,接口参数使用的是std::string类型。EXE 程序调用 DLL 中的接口时遇到"Debug Assertioni Failed"错误的问题。
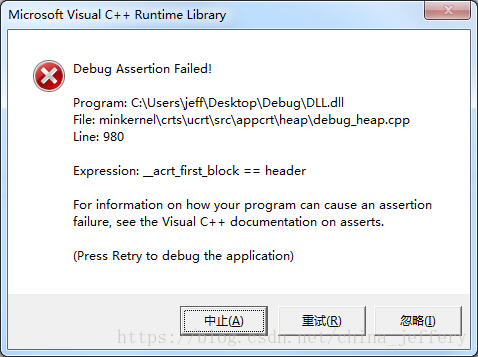
上面的错误提示表明触发了debug_heap.cpp文件中的一个调试断言(release模式下调用的是heap.cpp中的分配函数),该断言用于判断指针是否指向堆分配的内存块的第一块。在 release 模式下不会弹出这样的断言错误,程序可能会直接崩溃(崩溃相对来说还比较好排查),就怕出现其他不可预料的、难以排查的错误。
<原文出自: jiangxueqiao.com,请尊重原创>
现有 DLLUser.exe 调用 DLL.dll 中的 TestFun 函数,代码量非常小。DLL.dll 中 TestFun 函数定义:
1 | DLL_API void TestFun( std::string str) |
DLLUser.exe中调用TestFun函数:
1 | int _tmain(int argc, _TCHAR* argv[]) |
上面的代码运行之后程序就会弹出错误断言。原因是std::string在进行值传参的过程中会执行一次深拷贝,即:在堆上分配内存块,拷贝“test”到内存块中,然后将临时形参std::string对象传递到 dll 中,dll 中的TestFun函数在作用域结束后对临时形参进行释放时就出现了错误,因为尝试在dll的crt堆中释放由在exe的crt堆中分配的内存块。
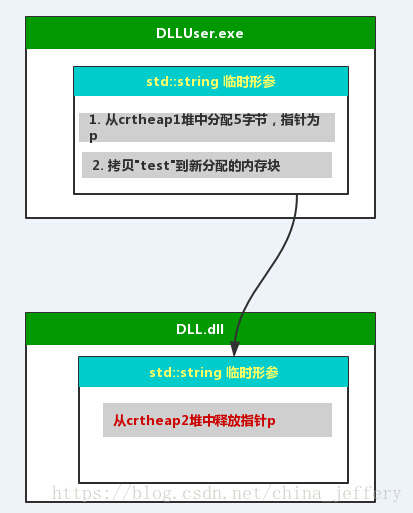
通过上面问题的分析,加上前面几篇文章对 Windows 内存体系的介绍,我们不难想出解决方案:让 std::string 统一在进程的默认堆上分配内存块,而不是在各个模块的crt堆上分配。
1 |
|
上面的代码使用自定义的内存分配器vm_allocator<char>定义了mystring类,我们只需要将TestFun函数接口中的std::string修改为mystring即可解决崩溃问题。
文章图片带有“CSDN”水印的说明:
由于该文章和图片最初发表在我的CSDN 博客中,因此图片被 CSDN 自动添加了水印。